Using Branches
Description
This section is from the "Version Control with Subversion" book, by Ben Collins-Sussman, Brian W. Fitzpatrick and C. Michael Pilato. Also available from Amazon: Version Control with Subversion.
At this point, you should understand how each commit creates an entire new filesystem tree (called a “revision”) in the repository. If you don't, go back and read about revisions in the section called “Revisions”.
For this chapter, we'll go back to the same example from
Chapter 1, Fundamental Concepts. Remember that you and your
collaborator, Sally, are sharing a repository that contains two
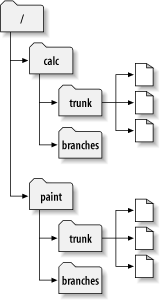
projects, paint and
calc. Notice that in Figure 4.2, “Starting repository layout”, however, each project
directory now contains subdirectories named
trunk and branches.
The reason for this will soon become clear.
As before, assume that Sally and you both have working
copies of the “calc” project. Specifically, you
each have a working copy of /calc/trunk.
All the files for the project are in this subdirectory rather
than in /calc itself, because your team has
decided that /calc/trunk is where the
“main line” of development is going to take
place.
Let's say that you've been given the task of implementing a
large software feature. It will take a long time to write, and
will affect all the files in the project. The immediate problem
is that you don't want to interfere with Sally, who is in the
process of fixing small bugs here and there. She's depending on
the fact that the latest version of the project (in
/calc/trunk) is always usable. If you
start committing your changes bit-by-bit, you'll surely break
things for Sally (and other team members as well).
One strategy is to crawl into a hole: you and Sally can stop
sharing information for a week or two. That is, start gutting
and reorganizing all the files in your working copy, but don't
commit or update until you're completely finished with the task.
There are a number of problems with this, though. First, it's
not very safe. Most people like to save their work to the
repository frequently, should something bad accidentally happen
to their working copy. Second, it's not very flexible. If you
do your work on different computers (perhaps you have a working
copy of /calc/trunk on two different
machines), you'll need to manually copy your changes back and
forth or just do all the work on a single computer. By that
same token, it's difficult to share your changes-in-progress
with anyone else. A common software development “best
practice” is to allow your peers to review your work as
you go. If nobody sees your intermediate commits, you lose
potential feedback and may end up going down the wrong path for
weeks before another person on your team notices. Finally, when
you're finished with all your changes, you might find it very
difficult to re-merge your final work with the rest of the
company's main body of code. Sally (or others) may have made
many other changes in the repository that are difficult to
incorporate into your working copy—especially if you
run svn update after weeks of
isolation.
The better solution is to create your own branch, or line of development, in the repository. This allows you to save your half-broken work frequently without interfering with others, yet you can still selectively share information with your collaborators. You'll see exactly how this works as we go.
Books on Subversion:
My Books

